Today, we are announcing AWS Lambda MicroVMs, a new serverless compute primitive within AWS Lambda that lets you run code generated by users or AI in isolated, stateful execution environments. You get virtual machine level isolation, near-instant launch and resume, and direct control over environment lifecycle and state, all without managing infrastructure or building expertise in complex virtualization technologies.
Lambda MicroVMs are powered by Firecracker , the same lightweight virtualization technology that has powered over 15 trillions of monthly Lambda function invocations. Why customers need this Over the past few years a new class of multi-tenant applications has emerged that all share the need to hand each end user their own dedicated execution environment in which to safely run code that the application developer did not write.
AI coding assistants, interactive code environments, data analytics platforms, vulnerability scanners, and game servers that run user-supplied scripts all fit this pattern. Building that capability today means making a difficult choice. Virtual machines deliver strong isolation but take minutes to start.
Containers launch in seconds, yet their shared-kernel architecture requires significant custom hardening to safely contain untrusted code. Functions as a service are optimized for event-driven, request-response workloads, but are not designed for long-running interactive sessions that need to retain environment state across user interactions. That leaves developers either accepting tradeoffs between performance and isolation, or investing significant engineering resources to build and operate custom virtualization infrastructure to achieve isolated execution while delivering low-latency experiences to end-users.
This presents an effort that demands deep expertise and pulls engineering time away from the product they are actually trying to build. Lambda MicroVMs is purpose-built for exactly this gap. Each MicroVM gives a single end user or session its own isolated environment that launches rapidly, retains memory and disk state for the length of the session, and pauses to a low idle cost when the user steps away.
Because the same Firecracker technology already underpins AWS Lambda Functions, you inherit the operational maturity of a service that has been running this stack at scale. Let’s try it out To get started, I navigated to the AWS Lambda console, where Lambda MicroVMs now appears in the left-hand navigation menu. I first need to create a MicroVM Image.
I packaged a Flask web app and its Dockerfile into a zip file, uploaded it to an Amazon Simple Storage Service (Amazon S3) bucket. My Flask API – app. py import logging from flask import Flask, jsonify app = Flask(name) logging.
basicConfig(level=logging. INFO) @app. route("/") def hello(): app.
logger. info("Received request to hello world endpoint") return jsonify(message="Hello, World!") if name == "main": app.
run(host="0. 0. 0.
0", port=5000) My Dockerfile FROM public. ecr. aws/lambda/microvms:al2023-minimal RUN dnf install -y python3 python3-pip && dnf clean all WORKDIR /app COPY requirements.
txt . RUN pip install --no-cache-dir -r requirements. txt COPY app.
py . EXPOSE 5000 CMD ["gunicorn", "--bind", "0. 0.
- 0:5000", "app:app"] I used the following command to create my MicroVM Image. aws lambda-microvms create-microvm-image \ --code-artifact uri=<path/to/s3/artifact.
zip> --name \ --base-image-arn arn:aws:lambda:us-east-1:aws:microvm-image:al2023-1 \ --build-role-arn You can also create the MicroVM Image in the AWS Console as in the image above. Once I ran the command, Lambda retrieved the zip, ran the Dockerfile, initialized the application, and took a Firecracker snapshot of the running disk and memory state.
Build logs streamed in real time to Amazon CloudWatch under /aws/lambda/microvms/ , and when the image was ready it appeared in the console with its Amazon Resource Name (ARN) and version number. aws lambda-microvms run-microvm \ --image-identifier arn:aws:lambda:::microvm-image:my-image \ --execution-role-arn arn:aws:iam:::role/MicroVMExecutionRole \ --idle-policy '{"maxIdleDurationSeconds":900,"suspendedDurationSeconds":300,"autoResumeEnabled":true}' Launching can also be done via the AWS Console or the CLI.
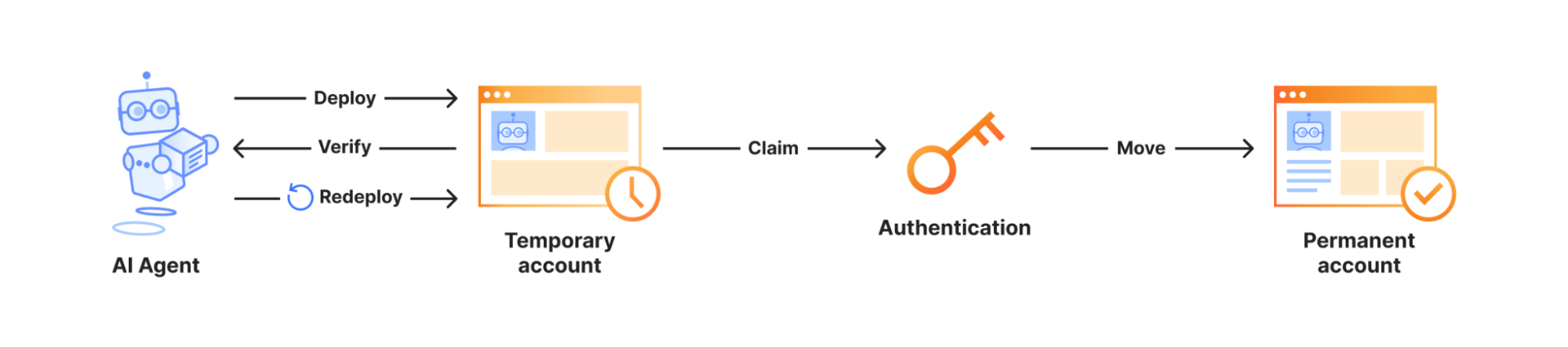
I passed the image ARN and an idle policy configured to auto-suspend after 15 minutes of inactivity and auto-resume on the next incoming request. No networking setup was required. Lambda assigned the MicroVM a unique ID, returned a dedicated endpoint URL, and started a new MicroVM with my Flask app already running, since it was resumed from a snapshot.
My Flask app was already running the moment the launch completed. One API call to get a fully initialized, bootstrapped compute environment. To send traffic, I generated a short-lived auth token with the CLI and attached it to a plain HTTPS request using the X-aws-proxy-auth header.
The request landed on my Flask app immediately. I then let the MicroVM sit idle past the suspend threshold, at which point the MicroVM was suspended, with its memory and disk state snapshotted and stored. I then sent another request, and it resumed with the application state fully intact.
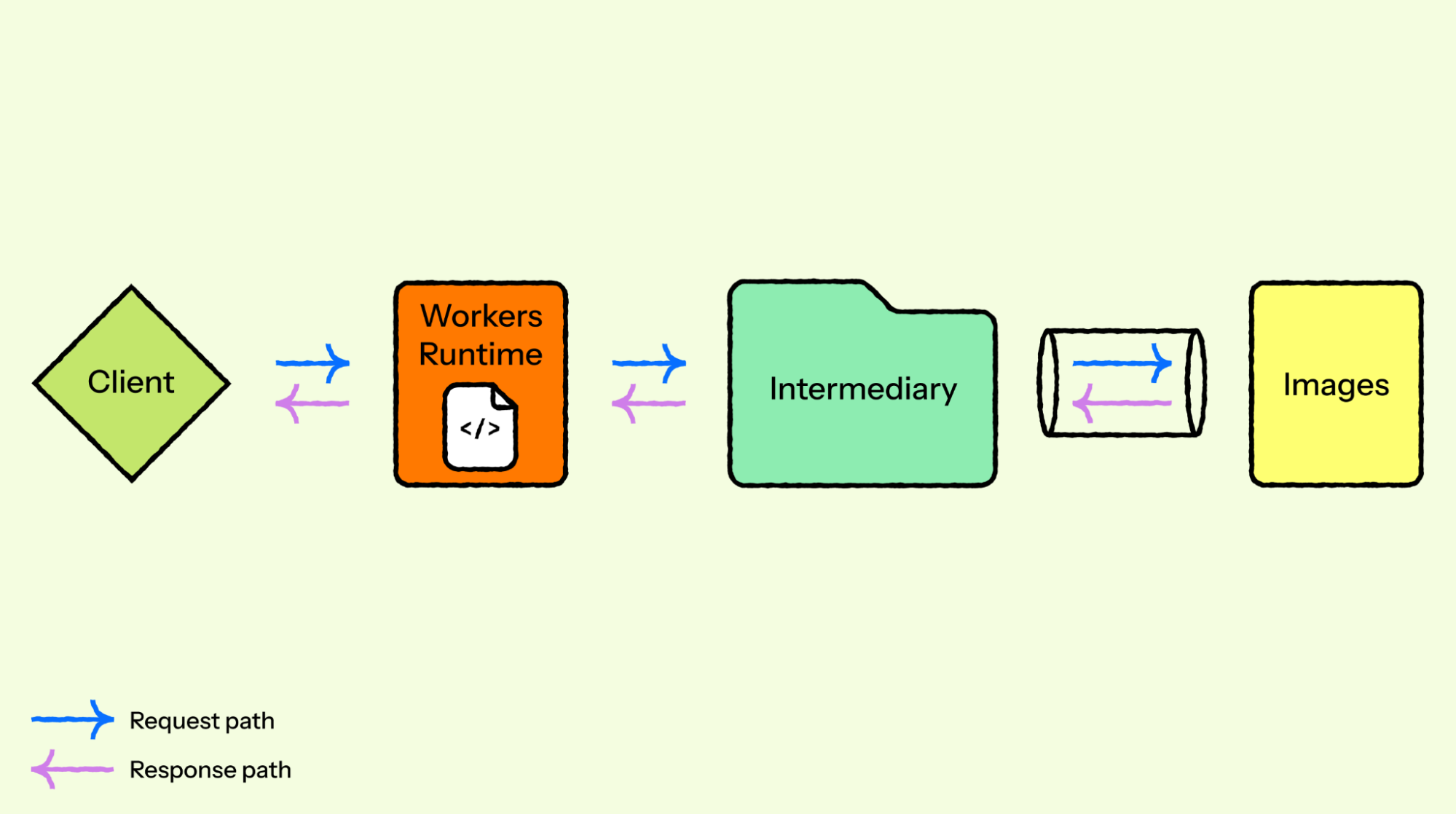
From the client side, the pause never happened. How it works Under the covers, Lambda MicroVMs delivers three capabilities that, until today, no single AWS compute service offered together. The first is virtual machine level isolation, which comes from Firecracker.
Each session runs in its own dedicated MicroVM with no shared kernel and no shared resources between users, so untrusted code supplied by one user is contained to their execution environment, without access to other environments or the underlying system. The second is rapid launch and resume.
Originally published at aws.amazon.com